Nils Reiter
DramaAnalysis on CRAN

We’re happy to announce that our R-Package on quantitative drama analysis, surprisingly called “DramaAnalysis”, is now available on the Comprehensive R Archive Network, CRAN. This makes the installation of the package a lot easier, because binary versions can be installed directly. Our R package assembles a number of reasonably documented functions that we find useful for drama analysis, with a focus on analysing the character speech. By providing an R package, we make experiments on textual drama data simpler and faster, in particular for literary scholars with limited programming experience. Still, as we do not provide a graphical user interface (cf. Reiter et al., 2015), some level of programming is required.
What is now available on CRAN is version 3.0.0, and it’s our first CRAN submission. Version 3.0.0 has been an extensive rewrite of many of the functions, to remedy issues that plagued us in the past (e.g., characters disappearing …). We also have a much clearer documentation now, and verified that it’s up to date again. If there are existing users of old versions of our package: Updating and installing is worth it, and easy:
install.packages("DramaAnalysis")
The core change is that we make use of so called S3 classes now in the package. This means, functions can verify on their own that they are called with the correct data input, and it also allows us to provide special versions of plotting functions tailored to a specific kind of data. In addition, it makes the code more modular, because we can concentrate some functionality instead of putting it in every function (e.g., the formatting of character names, so that they look nice for presentation).
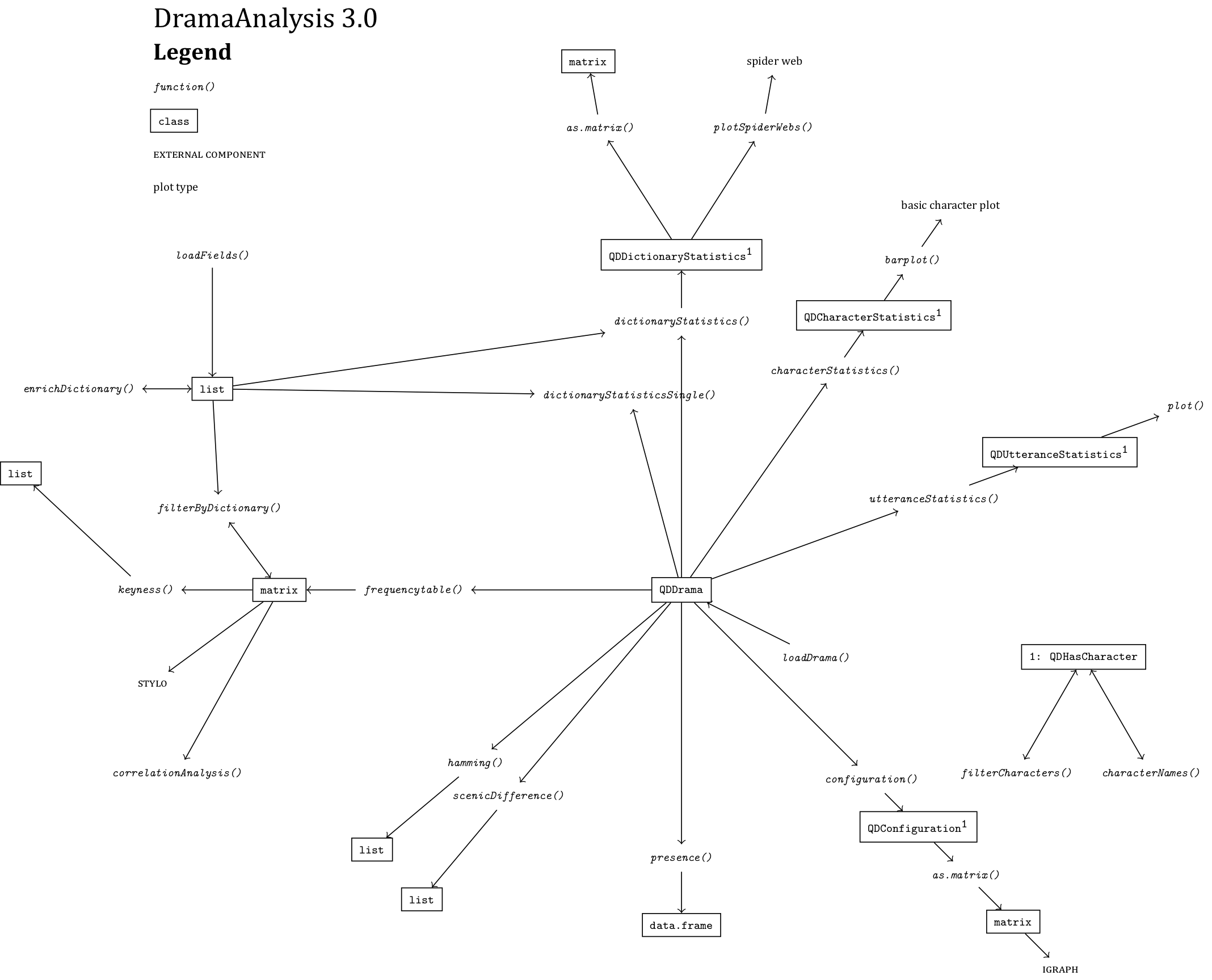
The above “treasure map” gives an overview of the different functions and can serve as a roadmap if you’re interested in exploring. We have also created a tutorial and uploaded all package documentation to our web page.
Links
- CRAN entry for DramaAnalysis
- Package documentation on the web
- Extensive written tutorial, downloadable as an eBook in ePub format
Data
As our focus interest is in the intersection between computational literary studies and computational linguistics, NLP-based character speech analysis is an important ingredient in our project. Therefore, the R package we provide works best with preprocessed data. Although it is possible to load XML/TEI data directly, we recommend loading data that we provide in the form of CSV files (currently available: German plays, Shakespeare plays). Both data sets have been taken from the DraCor repository, which is a collection of drama corpora in multiple languages. Data can be installed directly from the R console using one of these one-liners:
# Shakespeare corpus
installData("shakedracor")
# German-language plays
installData("qd")
Tool Landscape
The past years have shown continuous research on the quantitative analysis of dramatic texts, and both tool and method development have made progress. It’s great that our R package contributes to this.
The DraCor umbrella not only has assembled an impressive number of corpora, there are also several cool applications/tools that are available: Easy Linavis, for exploring character copresence networks, an R shiny app that allows cluster analysis, and, most importantly, a restful API that allows straightforward access to textual parts of the play (e.g., character speech by female characters) without dealing with XML. DraCor is headed by Frank Fischer.
Katharsis is a browser-based visual exploration tool that also integrates a sentiment analysis visualisation. It has been developed by Thomas Schmidt.