Technology
-
18th July 2019

We’re happy to announce that our R-Package on quantitative drama analysis, surprisingly called “DramaAnalysis”, is now available on the Comprehensive R Archive Network, CRAN. This makes the installation of the package a lot easier, because binary versions can be installed directly. Our R package assembles a number of reasonably documented functions that we find useful for drama analysis, with a focus on analysing the character speech. By providing an R package, we make experiments on textual drama data simpler and faster, in particular for literary scholars with limited programming experience. Still, as we do not provide a graphical user interface (cf. Reiter et al., 2015), some level of programming is required.
-
12th December 2018
Detecting Protagonists and Title Figures in Plays
In a recent paper1, we investigated how protagonists and title figures can be detected in German plays and which features are important for a machine learning model in order to conduct the classification. This post can be seen as a supplement to this paper.
-
The paper is orginally written in German and got translated into English by the publisher. ↩
-
-
12. Dezember 2018
Erkennung von Protagonisten und Titelfiguren in Dramen
In einem kürzlich erschienenen Artikel haben wir untersucht, inwieweit Protagonisten und Titelfiguren in deutschsprachigen Dramen automatisch erkannt werden können und welche Features einem Machine-Learning-Modell helfen, diese Klassifikation vorzunehmen. Dieser Post kann als Ergänzung zum Artikel gesehen werden.
-
19th April 2018
Annotating Coreference Chains (Part 3)
We have recently started to annotate coreference chains in dramatic texts. In this loose series of blog posts, we will discuss interesting findings and examples. This post revisits the annotation tool question – again.
-
20th December 2017
Annotating Coreference Chains (Part 2)
We have recently started to annotate coreference chains in dramatic texts. In this loose series of blog posts, we will discuss interesting findings and examples. This post revisits the annotation tool question.
-
8th December 2017
We have just released a new version of our R package for the quantitative analysis of plays, and want to highlight a few changes here. In QuaDramA, the R package is used for data analysis, after natural language processing has taken place. The package therefore relies on pre-processed corpora.
-
28th April 2017
Analysing Dramatic Figure Speech with R, Part 2
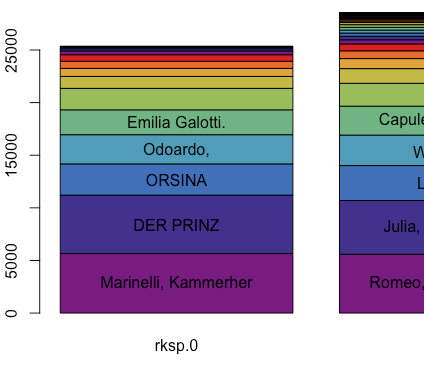
So far, we loaded dramatic texts into R with the help of a web service that converted from UIMA XMI files into CoNLL-like CSV files. Now that we have released version 0.4.1 of our DramaAnalysis R package, this is no longer necessary. Instead, we have integrated the needed Java code directly into the R package. This makes, we hope, using the R package much easier.
-
21st October 2016
Analysing Dramatic Figure Speech with R, Part 1
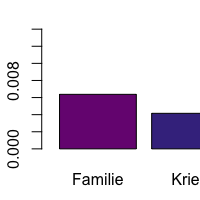
This guide describes how to analyse dramatic figure speech with R, using our linguistic preprocessing tools. It is written as a step-by-step guide and uses the (German) dramatic texts Romeo und Julia and Emilia Galotti as examples.
-
2nd October 2016
This post gives an overview of the current state of the technology we are using and how we plan to proceed in the future. All programs, scripts and components are available on our github page.