Nils Reiter
Annotating Coreference Chains (Part 3)
We have recently started to annotate coreference chains in dramatic texts. In this loose series of blog posts, we will discuss interesting findings and examples. This post revisits the annotation tool question – again.
Table of contents
Before going into details about interesting findings, we’ll have to revisit the annotation tool question, because there has been yet another development.
Our second attempt at annotated coreference chains was the use of WebAnno, and the conversion of the annotated chains into TEI. This has been discussed in the last part of this series.
WebAnno Experiences
While this worked well from a technical point of view, it quickly became possible that WebAnno is not well suited to deal with the coreferential properties in these texts. The two main issues are closely related, but there are few minor ones:
Many Entities
In addition to the characters that are active in the play, a large number of discourse entities appears and disappears frequently. This leads to a large number of coreference chains, that sometimes spread over long text passages. These are shown in WebAnno as lines that lie over the text, as shown in the screenshot below.
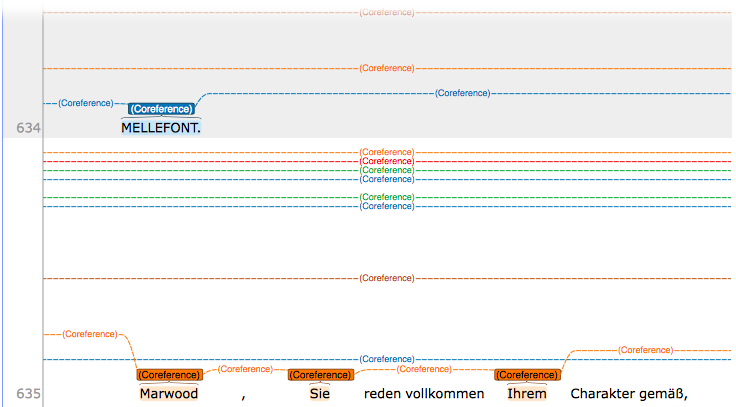
Screenshot of WebAnno with many coreference chains.
It becomes very hard for the annotators to distinguish the entities, and to find anaphora. In addition, there is only a limited amount of colors that are constantly changed (the color handling is apparently worked at the moment).
Long Texts
By default, WebAnno operates on sentences and shows only a few of them on one page. Increasing the number of shown sentences is only possible up to a certain extent – after that, browsers become unresponsive. In the extreme case, a coreference chain needs to be drawn from the very last to the very first sentence of a text, which results in endless scrolling. In some cases, the browser decides to reload the page in between (the reasons are not entirely clear to me), which means one has to start over with the scrolling.
Handling Mistakes
Due to the limited number of colors and unclear assignment of chains to entities, it happens frequently that a mention is assigned to the wrong chain. This is very hard to notice and even harder to correct, since it basically merges the chains. This is an irreversible operation, and annotators had to re-annotate entire chains.
Summary
In essence, it became clear quickly that we wanted to use WebAnno in a way and for texts for which it was not designed. As the curation view of WebAnno (to merge annotations made by multiple annotators) does not work for chain annotations (which I could have known before, but didn’t), WebAnno also lost much of its appeal.
A New Annotation Tool: CorefAnnotator
At the end, I decided to tentatively build a new annotation tool. At first, the goal was to see if I could create something usable within a day, in order not to sink a lot of hours into this. Luckily, it was possible to build on previous experiences (and code), such that it I decided to commit a few days fully.
And with that, a new annotation tool was born. It’s a desktop application written in Java, using UIMA to store annotations and to represent the documents. The main decision was not to annotate relations between mentions directly, i.e., we do not distinguish between cataphoric, anaphoric, or coreferential relations. Instead each mentions is associated with a text-external entity, and if chains are needed, they can be created during export.
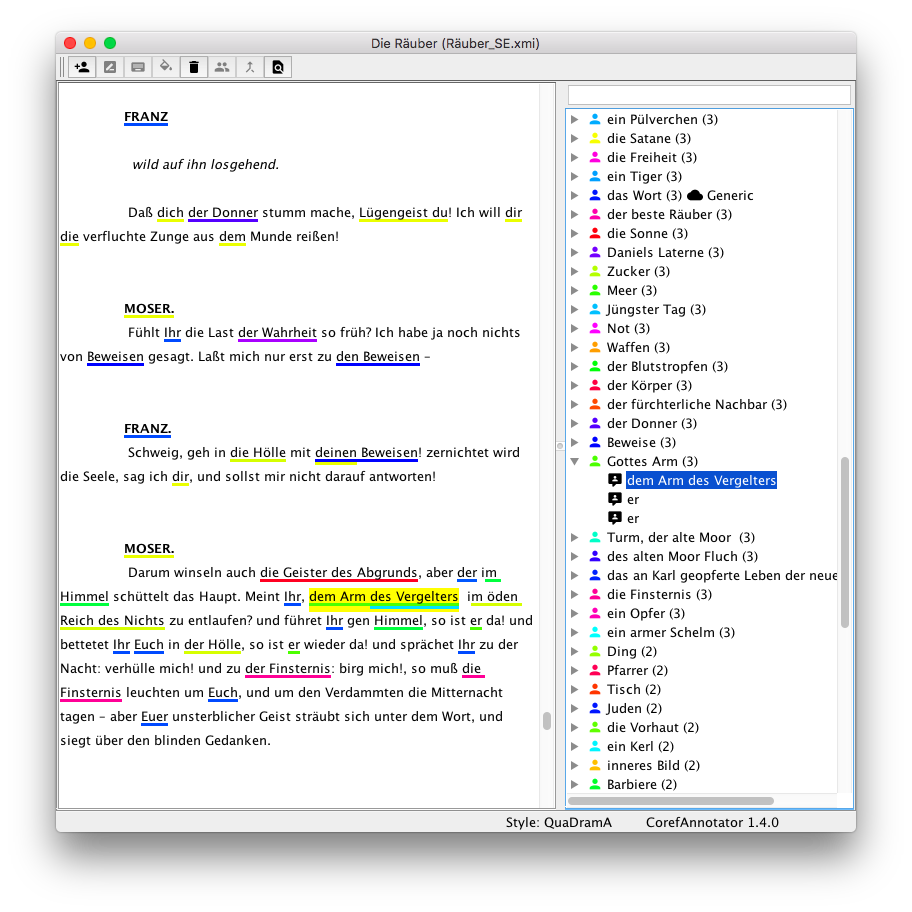
Screenshot of CorefAnnotator with many entities.
The tool supports the annotation of group entities (for plural pronouns as in the following example), and both entities and mentions can be marked with a number of attributes (generic, non-nominal).
[John]1 was cooking with [Sam]2. [They]3 had a lot of fun.
The creation of the tool also gave rise to a number of supporting functions that wouldn’t be possible with any existing annotation tool:
- Each entity can be assigned to a key on the keyboard. If text is selected, and the key is pressed, the tools annotates the selected span as a mention of the entity. When the number of entities grows, it becomes infeasible to assign a key to every entity (because there is a limited number of keys). Therefore, the entity list can be searched and pressing enter while an entity is highlighted adds the annotation. The core annotation functions can be done entirely using the keyboard.
- For any selected text span, a number of suggestions are shown in the context menu. These are entities that have been annotated in the context (surrounding text) or have mentions with the same span. Repeating annotation of the same surface string thus becomes very quick. An integration with a named entity recognizer has been added recently, to mark all named entities with the same surface form as mentions of the same entity.
- The entire text can be searched, using regular expressions. Findings can be selected and either added as mentions to an existing entity or annotated as mentions of a new entity.
- Since the tool is desktop-based, the text view can contain formatting information and, for instance, print stage directions in italic. This makes reading longer texts much easier for the annotators.
- All annotation operations can be reverted using an undo-function, for reverting accidental annotations quickly.
- Annotations created by different annotators can be compared (even more than than two). The compare view shows all disagreements in color, and allows quick identification of unclear or difficult cases. At this moment, the compare view covers only the spans of the mentions, and not the entity assignments, but this will be added in a future release.
Internally, all annotations are stored as UIMA annotations, and therefore with their character offsets. Texts can be imported from a few formats (including TEI/XML, but also plain text and conll), and also exported again. It is possible to import a document from TEI/XML, annotate coreferences in the annotation tool, and export it as the same TEI/XML again, but with added <rs>-elements to show the coreference.1 All TEI content is preserved during the annotation.
The annotation tool can be used for free and it is open source. It can be downloaded here. The annotation tool is currently in use within QuaDramA, CRETA, and hermA. Bug reports, suggestions and/or pull requests are highly welcome!
The next post in this series will really be about interesting cases, now that the tool question is decided once and for all.
-
There is one caveat though: If an annotation crosses the boundaries of an XML element, the exported “XML” document will not be valid XML. This lies in the nature of XML and can only be changed if the data structures become very different. ↩